Home » RDBMS Server » Performance Tuning » SQL vs. PLSQL
| SQL vs. PLSQL [message #204431] |
Mon, 20 November 2006 12:44  |
sebastianR
Messages: 33
Registered: August 2005
|
Member |
|
|
Hi there!
I have the task of inserting data basically from one table to another and I try as much as possible to use plain SQL whenever possible since I think that this is the best way to have oracle do all the optimizing work.
Now I have two conditions on how to accomplish this task:
1) performance
2) reusability of code
Please take a look at the JPG to understand how the INSERT-Statement looks like.
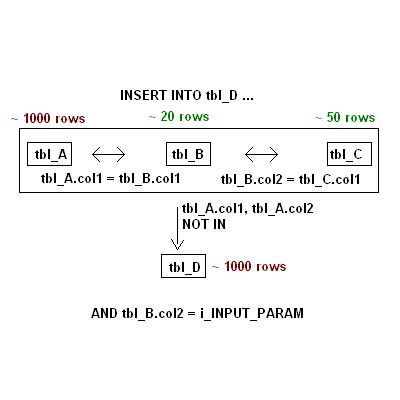
I simply join all the three tables, add a "NOT IN"-clause to filter entries in tbl_D and add a condition regarding the INPUT_PARAM:
INSERT INTO tbl_D
(col1, col2, col3, col4, col5, col6)
(SELECT
tbl_A.col1, tbl_A.col2, tbl_B.col2, tbl_A.col3, tbl_A.col4, tbl_C.col2
FROM
tbl_A, tbl_B, tbl_C
WHERE
tbl_A.col1 = tbl_B.col1
AND
tbl_B.col2 = tbl_C.col1
AND
(tbl_A.col1, tbl_A.col2)
NOT IN
(SELECT
tbl_D.col1, tbl_D.col2
FROM
tbl_D)
AND tbl_B.col2 = i_INPUT_PARAM
I think this solution performs well, but doesn't look like one could reuse much of it.
They want me to write getter-Methods whenever possible (so we can reuse code), which leads me to the following solution:
(CURSOR c_tbl_A)
WHILE c_tbl_A#FOUND LOOP
l_value1 := getSomeValByCol1(tbl_A.col1);
(CURSOR c_tbl_C) (where tbl_B.col2 = tbl_C.col1) ...
WHILE c_tbl_C#FOUND LOOP
IF (l_value1 = i_INPUT_PARAM)
AND
(c_tbl_A.col1, c_tbl_A.col2) NOT IN
(SELECT tbl_D.col1, tbl_D.col2
FROM tbl_D)
THEN
INSERT INTO tbl_D (...)
VALUES (c_tbl_A.col1, c_tbl_A.col2, l_value1, c_tbl_A.col3, c_tbl_A.col4, c_tbl_C.col2);
END IF;
END LOOP;
END LOOP;
I am not sure if this solution performs well or is more reusable than the other,
first of all I'd like to get your opinions on those approaches of mine.
Which one would you choose?
Why?
Is there a better solution?
Is performance an issue in this case?
Is it better to use SQL when possible instead of using cursors 'n stuff?
Thank you very much,
I appreciate every response,
yours,
Sebastian
|
|
|
|
| Re: SQL vs. PLSQL [message #204461 is a reply to message #204431] |
Mon, 20 November 2006 20:34  |
rleishman
Messages: 3728
Registered: October 2005
Location: Melbourne, Australia
|
Senior Member |
|
|
For your data volumes, performance is not really a consideration unless 100 people will be running this at the same time.
But the second option is just plain ridiculous. The single greatest strength of SQL over other languages is that it is goal-oriented. ie. You tell it what you want, not how to get it. This makes SQL (generally) easier to understand because you don't have to decypher intent from a procedural algorithm.
What you are doing in your second option is treating SQL like old fashioned VSAM databases: open a file, tell it which row(s) to give you, then process them (perhaps by repeating the process with other files). This technique has rightly gone the way of dinosaurs.
Personally, I would just go with the straight INSERT. If you have some common validation logic on new records that could be shared, then just use the SELECT part of the SQL in a cursor, and pass each row to a common writeback method that performs the validation. Or better yet, place the validation in a BEFORE INSERT trigger.
Ross Leishman
|
|
|
|
| Re: SQL vs. PLSQL [message #206362 is a reply to message #204461] |
Wed, 29 November 2006 13:55 |
sebastianR
Messages: 33
Registered: August 2005
|
Member |
|
|
Hi rleishman!
Thank you very much for your response!
I understand and agree with the aspects you have given in your reply, but still I am quite unsure if the way I want to realize the given task (using the simple SQL) is good.
To understand, why I still have doubts about it, please let me provide you an abstract overview about the context I am working in:
As mentioned in my first post, I basically want to insert data from one table in another.
While I am doing this, several things have to be done:
- open_history
- lock_rows
- delete_rows
- insert_rows (this is what my insert-statement is about!)
- close_history
These are the steps of one of three use-cases. Each of the use-case is quite similar. They mainly differ from each other in the way of selecting the data to process with (e.g. one time I get an ID as input, one time I get a name as input, ...)
My problem now is, that I will have to write all the needed SQL-statements for every use-case because the way I am getting the data is different in each use-case.
Consider this example:
INSERT INTO TABLE_1
(SELECT TABLE_2.col_2, TABLE_3.col_4, TABLE_4.col_1
FROM (SELECT DISTINCT TABLE_2.col_2, TABLE_3.col_4
FROM TABLE_2 INNER JOIN TABLE_3 ON TABLE_2.col_1 = TABLE_3.col_2
INNER JOIN TABLE4 ON TABLE_2.col2 = TABLE_4.col_3)
WHERE TABLE_2.col_4 = i_INPUT_PARAM
AND(TABLE_3.col_2, TABLE2.col_2) NOT IN(
SELECT col_1,
col_2
FROM TABLE_1));
INSERT INTO TABLE_1
(SELECT TABLE_2.col_2, TABLE_3.col_4, TABLE_4.col_1
FROM (SELECT DISTINCT TABLE_2.col_2, TABLE_3.col_4
FROM TABLE_2 INNER JOIN TABLE_3 ON TABLE_2.col_1 = TABLE_3.col_2
INNER JOIN TABLE4 ON TABLE_2.col2 = TABLE_4.col_3)
WHERE (TABLE_3.col_2, TABLE2.col_2) NOT IN(
SELECT col_1,
col_2
FROM TABLE_1));
In the first SELECT-Statement I have a condition regarding the INPUT-parameter, in the second version I don't have an INPUT-parameter. Everything else is all the same.
There is no possibility to write one SELECT-Statement which will work for both cases, is there?
I could however, split the INSERT part from the SELECT part (which I think is what you suggested), so I have one INSERT-procedure which gets its rows from different sources.
But then I'd again have to perfom the insert row-wise, like fetching all rows from a cursor and do the insert?
To summarize my situation, there are three use-cases, which differ in the way I have to get the data, and one task to perform with the data.
Do I have to write all the SQL-logic for every use-case?
Isn't this really uncool to have three times the (nearly) same SQL-code?
Is it bad to make a solution using plain SQL which is use-case oriented?
What about readability of complex SQL-statements?
One of my colleagues said, if I had to write 4 lines of commentary for each SQL-statement, so one could understand it, it's not very good.
I'm sorry if I mixed up soo many things at once, but I'm really unsure how to proceed, after I've read your opinion on the second kind of solution I suggested in my first post, since this is the way, code is usually written at my place, mainly because of easier readability, reusability and structual purposes.
Yours,
Sebastian
|
|
|
|
| Re: SQL vs. PLSQL [message #206365 is a reply to message #204431] |
Wed, 29 November 2006 14:22 |
michael_bialik
Messages: 621
Registered: July 2006
|
Senior Member |
|
|
If you want code reusability then use views:
CREATE OR REPLACE VIEW my_view AS
SELECT DISTINCT TABLE_2.col_2 x1, TABLE_3.col_4 x2, TABLE_4.col_1 x3, TABLE_2.col_4 x4
FROM TABLE_2 JOIN TABLE_3 ON TABLE_2.col_1 = TABLE_3.col_2
JOIN TABLE4 ON TABLE_2.col2 = TABLE_4.col_3
WHERE TABLE_2.col_4 = i_INPUT_PARAM
AND NOT EXISTS (SELECT 1 FROM TABLE_1
WHERE TABLE_1.col_1 = TABLE_3.col_2 AND TABLE_1.col_2 = TABLE2.col_2)
a. INSERT INTO TABLE_1
AS SELECT x1, x2, x3
FROM my_view
WHERE x4 = i_INPUT_PARAM;
b. INSERT INTO TABLE_1
AS SELECT x1, x2, x3
FROM my_view;
HTH.
As Ross said - using PLSQL is plain ridiculous.
|
|
|
|
|
|
Goto Forum:
Current Time: Thu May 02 08:17:20 CDT 2024
|

